Agenta
Agenta is the open-source platform that unites teams to collaboratively build and manage reliable LLM applications.
Visit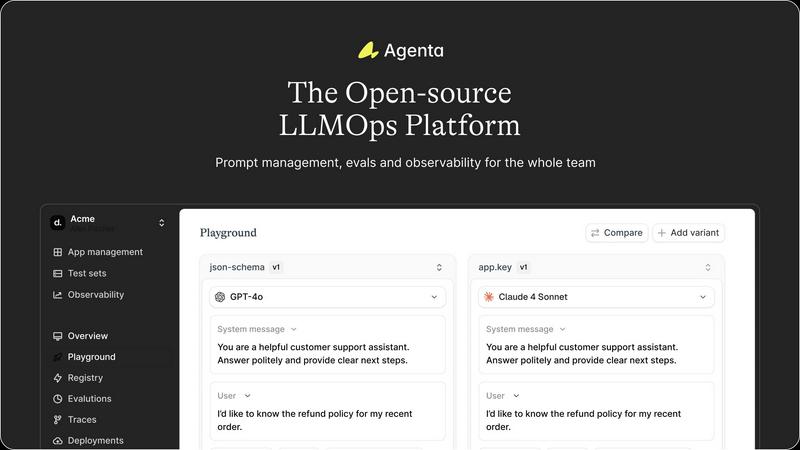
About Agenta
Agenta is an innovative, collaborative, open-source LLMOps platform designed to unify AI teams around the shared goal of building and shipping reliable large language model (LLM) applications. It effectively addresses the common challenges that hinder AI development, such as unpredictable model behavior, fragmented workflows, and isolated teams. By creating a centralized, integrated environment, Agenta allows developers, product managers, and subject matter experts to work together seamlessly. This transformation moves chaotic, ad-hoc processes into a structured, evidence-based workflow, resulting in improved efficiency and collaboration. Serving as the single source of truth for LLM development, Agenta centralizes the entire development lifecycle—from initial prompt experimentation and rigorous evaluation to production observability and debugging. Its core value proposition lies in enabling every team member to contribute their expertise safely, compare iterations systematically, and validate changes before they affect end users, ultimately fostering synergy and speeding up the delivery of robust AI products.
Features of Agenta
Centralized Prompt Management
Agenta allows teams to centralize their prompts, evaluations, and traces in one platform, eliminating the confusion of scattered information across various tools. This feature ensures that all team members have access to the same data, facilitating collaboration and reducing the risk of miscommunication.
Unified Playground
The unified playground enables teams to experiment with different prompts and models side-by-side. This feature supports a complete version history of prompts, allowing teams to track changes effectively and revert if necessary. It also ensures model agnosticism, permitting teams to utilize the best models from any provider without being locked into a single vendor.
Automated Evaluation Framework
Agenta replaces guesswork with systematic, evidence-based evaluation processes. Teams can create a structured methodology to run experiments, track results, and validate every change made to the models. This framework integrates seamlessly with any evaluator, whether it is a built-in evaluator or a custom solution.
Comprehensive Observability Tools
With advanced observability tools, Agenta allows teams to debug AI systems efficiently and gather user feedback in real time. Users can trace every request to find failure points, annotate traces collaboratively, and turn any trace into a test with a single click, thereby closing the feedback loop and enhancing the overall performance of AI applications.
Use Cases of Agenta
Collaborative Prompt Development
Agenta is ideal for teams looking to collaborate on prompt development. By allowing product managers, developers, and domain experts to work together in a single environment, teams can iterate and experiment with prompts efficiently, leading to better model performance.
Systematic Experimentation
Teams can utilize Agenta to create a systematic experimentation process. This use case is particularly beneficial for organizations that require rigorous testing of model iterations, ensuring that every change is validated and backed by evidence before deployment.
Enhanced Debugging and Feedback Gathering
Agenta's observability features enable teams to debug AI systems effectively. By tracing requests and annotating failures collaboratively, teams can gather valuable feedback from users and domain experts, which can then be integrated into future iterations of the model.
Agile Deployment of AI Applications
With Agenta, organizations can fast-track the deployment of AI applications. The platform's structured workflows and centralized resources help teams move from development to production swiftly, ensuring that they can ship reliable AI products with confidence.
Frequently Asked Questions
What is LLMOps and how does Agenta support it?
LLMOps, or Large Language Model Operations, refers to the practices and tools used to manage the lifecycle of LLM development. Agenta supports LLMOps by providing a collaborative platform that centralizes workflows, facilitates experimentation, and ensures systematic evaluation of model performance.
Can Agenta integrate with existing tools and technologies?
Yes, Agenta is designed to integrate seamlessly with a variety of frameworks and models, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to utilize their preferred tools while benefiting from Agenta's robust infrastructure.
Is Agenta suitable for teams of all sizes?
Absolutely. Agenta is built to accommodate teams of all sizes, from small startups to large enterprises. Its collaborative features and centralized tools enhance productivity regardless of the team's scale, making it an excellent choice for any organization involved in AI development.
How does Agenta ensure data security and privacy?
Agenta prioritizes data security and privacy by implementing best practices in software development and data management. The platform is open-source, allowing teams to review the code and ensure compliance with their security requirements. Additionally, Agenta offers features that help teams manage sensitive information responsibly throughout the development lifecycle.
Explore more in this category:
Similar to Agenta
HypeShare
Secure file transfer platform for sending large files fast — no signup required, end-to-end encryption, up to 10GB free.
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.
Bank Statement Engine
Free tool to convert PDF bank statements to Excel, CSV, JSON, QBO, OFX and QIF instantly. No signup, no limits, completely free.
online audio test
This comprehensive suite offers a collection of free, browser-based audio diagnostic tools designed for speed and clarity. With no downloads or sign-u
The Text Tool
Let’s work together to transform, clean, convert, and extract text instantly with over 200 free in-browser tools and zero sign-ups.