Fallom
Fallom empowers teams with complete visibility and real-time insights into every AI agent call and LLM operation.
Visit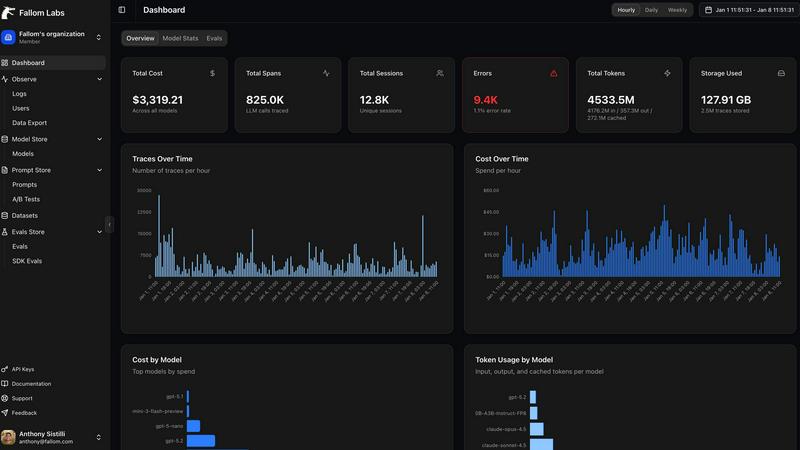
About Fallom
Fallom is the ultimate collaborative observability platform designed specifically for teams engaged in developing and operating AI applications. In an era where large language models (LLMs) and AI agents dominate, the complexity of interactions can overwhelm traditional monitoring systems. Fallom bridges this gap by providing a shared perspective for engineering, product, and business teams, enabling them to collectively view, comprehend, and enhance their AI workloads. It offers real-time, end-to-end tracing for every LLM interaction in production, capturing all critical details—from the initial user prompt to the model's output, including every tool call, token usage, latency metrics, and associated costs. This comprehensive visibility fosters collaboration among teams, allowing for swift debugging of complex agent failures, precise cost attribution across projects, and adherence to evolving regulations, all within a unified dashboard. With a single OpenTelemetry-native SDK, Fallom integrates seamlessly into your existing stack in just minutes, cultivating an environment of cooperation where all stakeholders have access to the contextual data they need to build reliable, efficient, and cost-effective AI experiences.
Features of Fallom
Real-Time Observability
Fallom provides real-time observability for AI agents, enabling teams to track tool calls and analyze timing effortlessly. This feature allows users to debug interactions confidently, ensuring that any anomaly is addressed promptly.
Cost Attribution
With Fallom's cost attribution feature, teams can track spending on a per-model, per-user, and per-team basis. This high level of transparency facilitates effective budgeting and chargeback processes, ensuring that financial resources are allocated efficiently.
Compliance Ready
Fallom ensures that organizations are prepared for compliance with regulatory standards such as the EU AI Act, SOC 2, and GDPR. It offers comprehensive audit trails, input/output logging, model versioning, and user consent tracking to meet these requirements.
Session Tracking
The session tracking feature groups traces by session, user, or customer, providing complete context for every interaction. This capability enhances collaboration and helps teams understand user behavior and engagement patterns more effectively.
Use Cases of Fallom
Debugging Complex Agent Failures
Teams can leverage Fallom to swiftly debug intricate failures in AI agents. By accessing real-time tracing data, engineers can pinpoint the exact stage of a process where issues arise, thereby reducing downtime and improving performance.
Cost Management and Budgeting
Organizations can use Fallom to manage their AI project budgets effectively. With detailed cost attribution, teams can analyze spending trends and allocate resources efficiently, ensuring that each project remains on budget.
Regulatory Compliance
Fallom is essential for organizations operating in regulated industries. By providing full audit trails and compliance features, teams can ensure that their AI applications meet legal requirements, thereby mitigating risks associated with non-compliance.
Performance Monitoring and Optimization
Fallom allows teams to monitor the performance of their LLMs in real-time. By analyzing latency metrics and identifying bottlenecks, teams can optimize AI workflows, enhancing the user experience and operational efficiency.
Frequently Asked Questions
What is Fallom and how does it work?
Fallom is a collaborative observability platform designed for AI applications, providing real-time, end-to-end tracing of LLM interactions. It captures comprehensive data, enabling teams to collaborate effectively on AI operations.
How does Fallom support compliance with regulations?
Fallom supports compliance by offering features such as audit trails, input/output logging, and user consent tracking. This ensures that organizations can meet regulatory requirements like GDPR and the EU AI Act.
Can Fallom integrate with my existing tech stack?
Yes, Fallom integrates seamlessly into your existing technology stack in just minutes using a single OpenTelemetry-native SDK. This allows for quick setup and minimal disruption to ongoing operations.
What kind of insights can I gain from using Fallom?
Fallom provides valuable insights into AI operations, including performance metrics, cost analysis, and user behavior. Teams can utilize this data for debugging, optimizing workflows, and making informed decisions.
Explore more in this category:
Similar to Fallom

GeoRank
Planning a relocation or long-term stay abroad? Compare places on sunshine, cost, tax, visa access for your passport, then ask AI about your short

Video2URL
Turn videos into clean, shareable, trackable URLs in seconds.
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.
Bank Statement Engine
Free tool to convert PDF bank statements to Excel, CSV, JSON, QBO, OFX and QIF instantly. No signup, no limits, completely free.
Flowton
Pick a goal, label time spent as Up time or Down time. Improve the ratio.
online audio test
This comprehensive suite offers a collection of free, browser-based audio diagnostic tools designed for speed and clarity. With no downloads or sign-u
Social Fetch
Social media research API: scrape profiles, posts, hashtags, comments, and metrics. Social data API with JSON, cursor pagination, 20+ networks.