Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta is the open-source platform that unites teams to collaboratively build and manage reliable LLM applications.
Last updated: March 1, 2026
OpenMark AI helps your team benchmark over 100 AI models on your specific task to find the best one for cost, speed, and quality.
Last updated: March 26, 2026
Visual Comparison
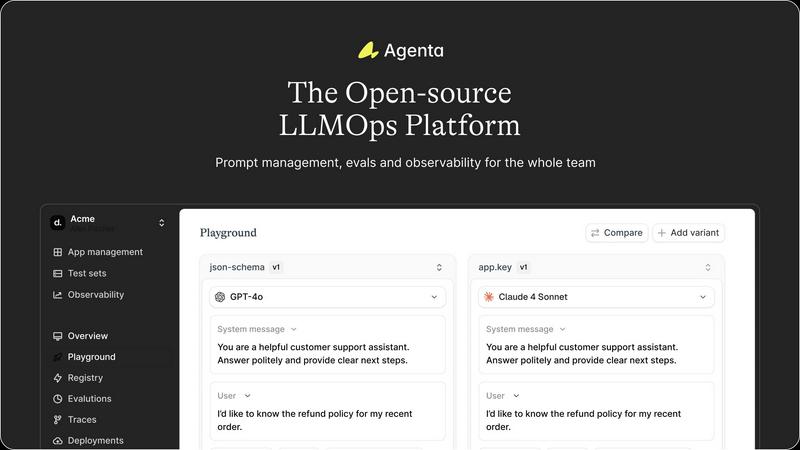
Agenta
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta allows teams to centralize their prompts, evaluations, and traces in one platform, eliminating the confusion of scattered information across various tools. This feature ensures that all team members have access to the same data, facilitating collaboration and reducing the risk of miscommunication.
Unified Playground
The unified playground enables teams to experiment with different prompts and models side-by-side. This feature supports a complete version history of prompts, allowing teams to track changes effectively and revert if necessary. It also ensures model agnosticism, permitting teams to utilize the best models from any provider without being locked into a single vendor.
Automated Evaluation Framework
Agenta replaces guesswork with systematic, evidence-based evaluation processes. Teams can create a structured methodology to run experiments, track results, and validate every change made to the models. This framework integrates seamlessly with any evaluator, whether it is a built-in evaluator or a custom solution.
Comprehensive Observability Tools
With advanced observability tools, Agenta allows teams to debug AI systems efficiently and gather user feedback in real time. Users can trace every request to find failure points, annotate traces collaboratively, and turn any trace into a test with a single click, thereby closing the feedback loop and enhancing the overall performance of AI applications.
OpenMark AI
Plain Language Task Description
Describe the specific task you need an AI model to perform using simple, natural language—no coding required. Whether it's data extraction, content classification, translation, or building a RAG pipeline, you can define your exact success criteria. The platform then translates this into structured prompts to ensure every model in your benchmark is tested against the same, relevant challenge, fostering a shared understanding across technical and non-technical team members.
Multi-Model Benchmarking in One Session
Run your defined task against a wide selection of models from leading providers like OpenAI, Anthropic, and Google in a single, unified session. This eliminates the tedious process of manually configuring separate API keys and writing individual test scripts for each model. Your team gets immediate, side-by-side comparisons, streamlining the evaluation process and enabling faster, consensus-driven decision-making.
Comprehensive Performance Metrics
Move beyond marketing claims with metrics derived from real API calls. Compare not just token cost, but the actual cost per request, latency, and a scored assessment of output quality for your task. Most importantly, OpenMark runs multiple iterations to measure stability and variance, showing you how consistent a model's performance is. This holistic view ensures your team chooses a model that is both cost-effective and reliably high-quality.
Hosted Credits System
Simplify collaboration and budgeting with a unified credits system. Team members can run benchmarks without needing to provision or share sensitive individual API keys from different vendors. This centralized approach makes it easy to manage testing costs, track usage across projects, and ensure everyone is working from the same financial and operational framework, enhancing team synergy.
Use Cases
Agenta
Collaborative Prompt Development
Agenta is ideal for teams looking to collaborate on prompt development. By allowing product managers, developers, and domain experts to work together in a single environment, teams can iterate and experiment with prompts efficiently, leading to better model performance.
Systematic Experimentation
Teams can utilize Agenta to create a systematic experimentation process. This use case is particularly beneficial for organizations that require rigorous testing of model iterations, ensuring that every change is validated and backed by evidence before deployment.
Enhanced Debugging and Feedback Gathering
Agenta's observability features enable teams to debug AI systems effectively. By tracing requests and annotating failures collaboratively, teams can gather valuable feedback from users and domain experts, which can then be integrated into future iterations of the model.
Agile Deployment of AI Applications
With Agenta, organizations can fast-track the deployment of AI applications. The platform's structured workflows and centralized resources help teams move from development to production swiftly, ensuring that they can ship reliable AI products with confidence.
OpenMark AI
Validating Model Choice Before Development
Development teams can collaboratively test multiple LLMs on a prototype task before committing engineering resources. This ensures the selected model fits the technical requirements and budget constraints, preventing costly rework later and aligning the entire team on a proven, data-backed foundation for the upcoming build phase.
Optimizing Cost-Efficiency for Production Features
Product and engineering leads can work together to find the most cost-effective model for a live feature without sacrificing quality. By benchmarking on real user prompts, teams can identify if a smaller, less expensive model performs just as well as a premium one for their specific use case, directly improving the feature's ROI through cooperative analysis.
Ensuring Output Consistency and Reliability
Teams building features where consistent outputs are critical—such as data extraction pipelines or automated customer support—can use OpenMark to stress-test models. By analyzing variance across multiple runs, the team can collaboratively identify and select a model that delivers stable, predictable results, building trust in the AI component's performance.
Comparing New Model Releases
When a new model version is released, teams can quickly benchmark it against their currently used model on their exact tasks. This facilitates a streamlined, evidence-based upgrade discussion, allowing the team to collaboratively assess if the new model offers meaningful improvements in quality, speed, or cost for their application.
Overview
About Agenta
Agenta is an innovative, collaborative, open-source LLMOps platform designed to unify AI teams around the shared goal of building and shipping reliable large language model (LLM) applications. It effectively addresses the common challenges that hinder AI development, such as unpredictable model behavior, fragmented workflows, and isolated teams. By creating a centralized, integrated environment, Agenta allows developers, product managers, and subject matter experts to work together seamlessly. This transformation moves chaotic, ad-hoc processes into a structured, evidence-based workflow, resulting in improved efficiency and collaboration. Serving as the single source of truth for LLM development, Agenta centralizes the entire development lifecycle—from initial prompt experimentation and rigorous evaluation to production observability and debugging. Its core value proposition lies in enabling every team member to contribute their expertise safely, compare iterations systematically, and validate changes before they affect end users, ultimately fostering synergy and speeding up the delivery of robust AI products.
About OpenMark AI
OpenMark AI is a collaborative web platform designed to empower development and product teams to make data-driven decisions when integrating AI. It eliminates the guesswork from selecting the right large language model (LLM) for a specific feature or workflow. The core value proposition is enabling teams to benchmark models side-by-side on their exact tasks using plain language, without the need for complex setup or managing multiple API keys. By running the same prompts against a vast catalog of over 100 models in a single session, teams can compare critical real-world metrics like cost per request, latency, scored output quality, and—crucially—output stability across repeat runs. This focus on consistency reveals performance variance, ensuring you select a reliable model, not just one that got lucky once. OpenMark AI is built for pre-deployment validation, helping teams collaboratively find the optimal balance of cost-efficiency and quality for their unique application before any code is shipped.
Frequently Asked Questions
Agenta FAQ
What is LLMOps and how does Agenta support it?
LLMOps, or Large Language Model Operations, refers to the practices and tools used to manage the lifecycle of LLM development. Agenta supports LLMOps by providing a collaborative platform that centralizes workflows, facilitates experimentation, and ensures systematic evaluation of model performance.
Can Agenta integrate with existing tools and technologies?
Yes, Agenta is designed to integrate seamlessly with a variety of frameworks and models, including LangChain, LlamaIndex, and OpenAI. This flexibility allows teams to utilize their preferred tools while benefiting from Agenta's robust infrastructure.
Is Agenta suitable for teams of all sizes?
Absolutely. Agenta is built to accommodate teams of all sizes, from small startups to large enterprises. Its collaborative features and centralized tools enhance productivity regardless of the team's scale, making it an excellent choice for any organization involved in AI development.
How does Agenta ensure data security and privacy?
Agenta prioritizes data security and privacy by implementing best practices in software development and data management. The platform is open-source, allowing teams to review the code and ensure compliance with their security requirements. Additionally, Agenta offers features that help teams manage sensitive information responsibly throughout the development lifecycle.
OpenMark AI FAQ
How does OpenMark AI calculate the quality score?
The quality score is determined by evaluating the model's outputs against the specific task you defined. While the exact scoring methodology is tailored to the task type, it generally involves automated checks for accuracy, completeness, and adherence to your instructions. This objective scoring helps teams move beyond subjective opinions to a shared, quantitative understanding of model performance.
Do I need my own API keys to use OpenMark AI?
No, you do not need to configure or manage separate API keys from providers like OpenAI or Anthropic. OpenMark operates on a hosted credits system. You purchase credits through the platform and use them to run benchmarks, which are executed via OpenMark's own integrations. This simplifies setup and secures your team's workflow.
What is the benefit of testing for stability/variance?
Testing stability by running the same prompt multiple times shows you whether a model's good output was a lucky one-off or a reliable result. High variance means the model is inconsistent, which is a major risk for production features. This insight allows your team to choose a predictably good performer, ensuring a better user experience and reducing operational headaches.
Can I use OpenMark for tasks beyond simple text generation?
Absolutely. OpenMark is designed for a wide variety of task-level benchmarking, including complex workflows like classification, translation, data extraction, question answering, RAG (Retrieval-Augmented Generation) systems, and even image analysis with multimodal models. Describe your collaborative project's needs, and you can benchmark models suited for that specific challenge.
Alternatives
Agenta Alternatives
Agenta is an open-source platform designed for collaborative development and management of reliable LLM applications. As teams strive to enhance their AI projects, they often encounter challenges like unpredictable model behavior and disjointed workflows. This prompts users to seek alternatives that might better suit their needs, whether due to pricing structures, feature sets, or specific platform requirements. When evaluating options, it’s essential to consider factors such as ease of collaboration, the flexibility of experimentation, and the robustness of evaluation frameworks to ensure a smooth transition and continued productivity.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level benchmarking of large language models. It helps teams compare cost, speed, quality, and stability across 100+ LLMs in a single browser-based session, using real API calls to inform pre-deployment decisions. Teams often explore alternatives for various reasons, such as different budget constraints, a need for on-premise deployment, or requirements for more specialized testing features like automated regression or deeper performance analytics. The ideal tool varies based on a project's specific phase and technical needs. When evaluating other solutions, consider the scope of model coverage, the transparency of cost calculations, the depth of quality assessment metrics, and whether the platform provides genuine, uncached performance data. The goal is to find a benchmarking partner that offers clear, actionable insights tailored to your team's workflow and collaboration style.