Agent to Agent Testing Platform vs LLMWise
Side-by-side comparison to help you choose the right product.
Agent to Agent Testing Platform
Agent to Agent Testing Platform ensures comprehensive evaluation of AI agents across various modes for safety and.
Last updated: February 28, 2026
LLMWise
Unify your team's AI tools with one smart API that automatically picks the best model for every task.
Last updated: February 28, 2026
Visual Comparison
Agent to Agent Testing Platform
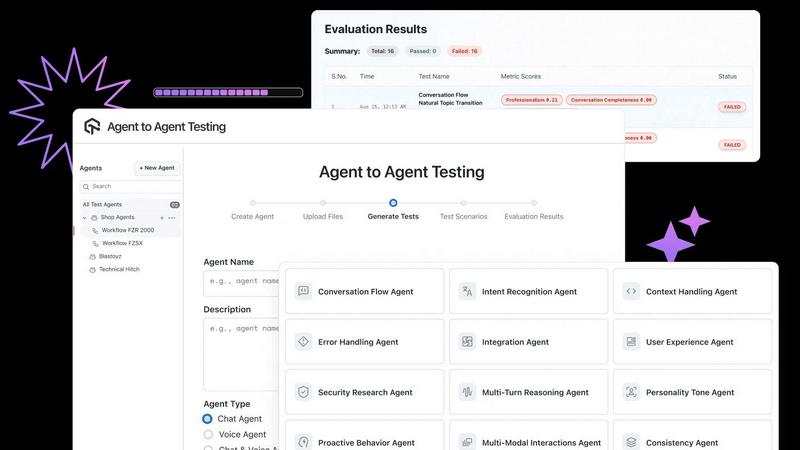
LLMWise
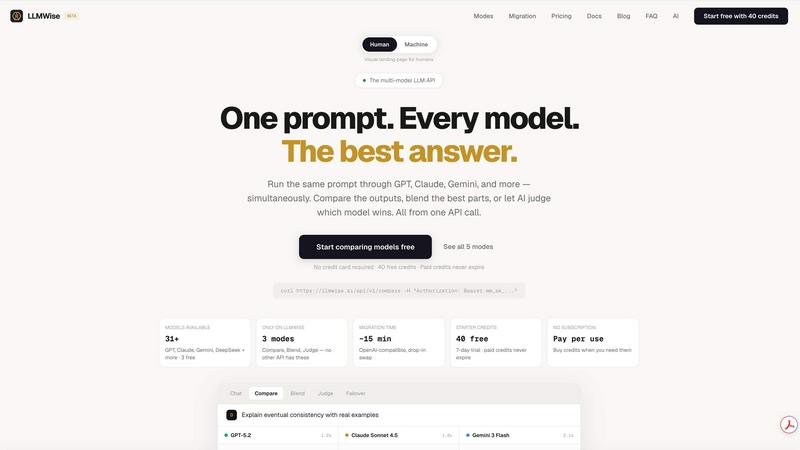
Feature Comparison
Agent to Agent Testing Platform
Automated Scenario Generation
The platform employs automated scenario generation to create diverse test cases that simulate various interactions, including chat, voice, and hybrid scenarios. This feature ensures comprehensive coverage of different user journeys, allowing for a deeper understanding of agent performance across multiple contexts.
True Multi-Modal Understanding
Beyond just text, the Agent to Agent Testing Platform supports various input types, such as images, audio, and video. Users can define detailed requirements or upload PRDs, helping to evaluate the agent's expected output in scenarios that closely mirror real-world interactions, thus enhancing the testing process.
Autonomous Test Scenario Generation
The platform provides access to a library of hundreds of pre-defined scenarios while also allowing users to create custom scenarios. This flexibility helps in assessing various aspects of the agent, such as personality tone, data privacy considerations, and intent recognition capabilities, ensuring that the agent meets specific operational needs.
Diverse Persona Testing
By leveraging a variety of personas, the platform simulates different end-user behaviors and interactions during testing. This feature ensures that the AI agent performs effectively for diverse user types, whether they are international callers or digital novices, thereby enhancing user experience across the board.
LLMWise
Intelligent Model Routing
LLMWise's smart routing acts as your AI conductor, analyzing each prompt and automatically directing it to the most suitable model from its vast catalog. This means code generation tasks are sent to the best coding model, creative briefs to the most eloquent writer, and analytical questions to the most logical reasoner. This feature removes the guesswork and manual switching between different provider dashboards, allowing your team to focus on building great products instead of managing AI infrastructure.
Compare, Blend, and Judge Modes
This suite of orchestration tools empowers teams to harness the collective intelligence of multiple models. Compare mode runs a single prompt across several models simultaneously, presenting their answers side-by-side with metrics on speed, cost, and length for easy evaluation. Blend mode takes this further by synthesizing the best parts of each model's output into one superior, cohesive answer. Judge mode enables models to critique and evaluate each other's responses, providing an automated layer of quality assurance.
Resilient Circuit-Breaker Failover
LLMWise ensures your application's AI capabilities never break. It includes an intelligent circuit-breaker system that monitors all connected providers in real-time. If a primary model or provider experiences high latency or an outage, traffic is instantly and automatically rerouted to a predefined backup model. This built-in redundancy guarantees high availability and reliability for production applications, giving your team and your users uninterrupted service.
Advanced Testing & Optimization Suite
Teams can systematically improve their AI implementations with LLMWise's built-in testing tools. Create benchmark suites and run batch tests across models to measure performance on your specific prompts. Set optimization policies that automatically prioritize speed, cost, or accuracy for different types of requests. Automated regression checks help ensure that updates to models or prompts don't degrade the quality of your outputs, fostering a culture of continuous improvement and stable deployments.
Use Cases
Agent to Agent Testing Platform
Comprehensive QA for Enterprises
Organizations can utilize the Agent to Agent Testing Platform for thorough quality assurance of AI agents before launching them into production. This ensures that the agents meet performance standards and are free from biases or toxicity, providing a reliable user experience.
Risk Assessment in AI Interactions
The platform's regression testing capabilities allow enterprises to conduct end-to-end assessments of AI agents, focusing on risk scoring. This feature highlights potential areas of concern, enabling teams to prioritize critical issues and optimize their testing strategies effectively.
Continuous Integration and Deployment
The seamless integration with HyperExecute enables organizations to run large-scale tests with minimal setup. This feature supports continuous integration and deployment pipelines, ensuring that AI agents are consistently evaluated, and any issues are promptly addressed.
Performance Optimization
With actionable evaluations available in minutes, organizations can access detailed reports on AI agent performance. This information allows teams to optimize conversational flows and improve interaction dynamics, thereby enhancing the overall effectiveness of the AI agents.
LLMWise
Development and Prototyping
Developers can rapidly prototype AI features using the 30 permanently free models available at zero cost. This allows teams to experiment with different model capabilities, test prompt effectiveness, and build proof-of-concepts without any financial commitment. The compare mode is invaluable for debugging prompt issues by instantly seeing how different models interpret the same instruction, saving hours of trial and error.
Production Application Resilience
For teams running customer-facing AI applications, LLMWise's failover routing is critical. It ensures that if a primary AI service like GPT-4 has an outage, user requests are seamlessly handled by a backup model like Claude or Gemini, preventing downtime and maintaining a positive user experience. This turns a potential crisis into a minor, automated blip that your operations team doesn't need to manually manage.
Cost-Optimized AI Operations
Companies with existing API credits from major providers can use LLMWise's BYOK (Bring Your Own Keys) feature to plug in their keys and immediately benefit from smart routing and failover without changing their billing setup. This synergy between existing investments and new orchestration capabilities can lead to significant cost reductions, often over 40%, by ensuring the most cost-effective model is used for each task.
Content Creation and Evaluation
Marketing and content teams can use the blend and judge modes to produce higher-quality drafts. A single request can generate variations from multiple creative models, then synthesize the strongest elements into a final piece. Judge mode can then provide automated feedback on tone, clarity, and alignment with brand guidelines, creating a collaborative workflow between human creativity and AI assistance.
Overview
About Agent to Agent Testing Platform
Agent to Agent Testing Platform is a groundbreaking AI-native quality assurance framework designed specifically to assess the performance and behavior of AI agents in real-world environments. As AI agents become increasingly autonomous and capable of dynamic interactions, traditional quality assurance models that cater to static software fail to address the complexities of these systems. This platform offers a comprehensive solution that goes beyond simple prompt-level evaluations, enabling businesses to conduct thorough assessments of multi-turn conversations across various modalities, including chat, voice, and phone interactions. By utilizing 17+ specialized AI agents, the platform identifies long-tail failures, edge cases, and interaction patterns that manual testing might overlook. The autonomous synthetic user testing feature simulates a multitude of production-like interactions, ensuring that AI agents are validated and ready for production rollouts. Ultimately, this platform empowers enterprises to ensure reliability, performance, and ethical considerations such as bias and toxicity in their AI systems.
About LLMWise
LLMWise is the ultimate orchestration platform for developers and teams building with large language models. It eliminates the complexity of managing multiple AI providers by offering a single, unified API to access over 62 models from 20 leading providers, including OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek. The core value proposition is intelligent, task-based routing: you send a prompt, and LLMWise automatically selects the optimal model for the job, whether it's coding with GPT, creative writing with Claude, or translation with Gemini. This collaborative approach ensures you always get the best possible output without vendor lock-in.
Built for developers who demand performance and reliability, LLMWise goes beyond simple routing with powerful orchestration modes like side-by-side comparison, output blending, and model-judged evaluations. It ensures your applications are always resilient with automatic failover routing if a provider experiences downtime. With a flexible, credit-based pricing model and the option to bring your own API keys (BYOK), teams can significantly reduce costs while gaining unparalleled flexibility. Start with 20 free credits and access 30 permanently free models to prototype, test, and build with zero commitment.
Frequently Asked Questions
Agent to Agent Testing Platform FAQ
What types of AI agents can be tested using this platform?
The Agent to Agent Testing Platform supports various AI agents, including chatbots, voice assistants, and phone caller agents. This versatility allows organizations to validate a wide range of AI applications in their systems.
How does the platform ensure the detection of long-tail failures?
By employing over 17 specialized AI agents for multi-agent test generation, the platform uncovers long-tail failures and edge cases that manual testing may miss. This approach ensures a more robust evaluation of AI behavior across diverse scenarios.
Can I create custom test scenarios?
Yes, the platform offers the ability to create custom test scenarios in addition to accessing a library of predefined scenarios. This feature allows users to tailor tests to specific requirements and operational contexts.
How quickly can I receive insights after testing?
The Agent to Agent Testing Platform delivers actionable evaluations in minutes, providing organizations with deep visibility into performance metrics, conversational dynamics, and overall agent effectiveness, enabling swift optimization efforts.
LLMWise FAQ
How does the pricing work?
LLMWise uses a simple, pay-as-you-go credit system with no monthly subscriptions. You start with 20 free trial credits that never expire. After that, you purchase credit packs. You are only charged credits when you use a paid model; the 30 free models always cost 0 credits. You also have the option to use your own existing API keys from providers (BYOK), in which case you pay the provider directly at their rates and only use LLMWise credits for the orchestration features.
What are the free models for?
The 30+ free models serve multiple strategic purposes. They are perfect for initial prototyping and development, allowing you to build and test without cost. They act as a smart fallback layer for non-critical traffic or during retries if paid models fail. They are also essential for benchmarking, enabling you to compare the quality and performance of free versus paid models on your specific tasks before deciding where to route production traffic.
How quickly can I integrate LLMWise?
You can be up and running in under two minutes. The process involves signing up for an account to receive your free credits, generating a single API key from your dashboard, and then making your first request using the provided Python/TypeScript SDKs or cURL examples. This unified API approach means you replace multiple provider-specific integrations with one simple connection.
What happens if a model provider is down?
LLMWise's circuit-breaker failover system handles this automatically. The platform continuously monitors the health and latency of all connected model providers. If a primary model becomes unavailable or too slow, the system instantly reroutes your application's requests to a pre-configured backup model from a different provider. This ensures your application's AI features remain operational without any manual intervention required from your team.
Alternatives
Agent to Agent Testing Platform Alternatives
The Agent to Agent Testing Platform is an innovative AI-native quality assurance framework that focuses on validating the behavior of AI agents in real-world scenarios. This platform is essential in the realm of AI Assistants, as it addresses the complexities of agent interactions across various modalities, such as chat, voice, and phone. As organizations adopt AI systems that are increasingly autonomous and dynamic, they often seek alternatives due to factors like pricing concerns, feature sets, and specific platform requirements that may not be fully addressed by the Agent to Agent Testing Platform. When exploring alternatives, it's crucial to consider the specific needs of your team and the nuances of your projects. Look for solutions that offer comprehensive testing capabilities, scalability, and robust validation mechanisms. Additionally, prioritize platforms that emphasize collaboration and synergy, ensuring that all stakeholders can work together effectively to achieve high-quality outcomes in AI performance and compliance.
LLMWise Alternatives
LLMWise is a unified API platform in the AI assistants category, designed to give developers a single access point to leading large language models like GPT, Claude, and Gemini. Its core innovation is intelligent auto-routing, which automatically selects the best-suited model for each specific prompt to optimize performance. Users often explore alternatives for various reasons, such as different pricing structures, the need for specific platform integrations, or a desire for a different set of management and testing features. Some teams may prioritize a different balance between cost, control, and convenience. When evaluating other solutions, it's wise to consider your team's primary needs. Key factors include the flexibility of the API, the depth of analytics and testing tools, the robustness of failover systems, and the overall pricing model. The goal is to find a tool that enhances your team's collaborative workflow without adding unnecessary complexity.