ImageBind by Meta AI
About ImageBind by Meta AI
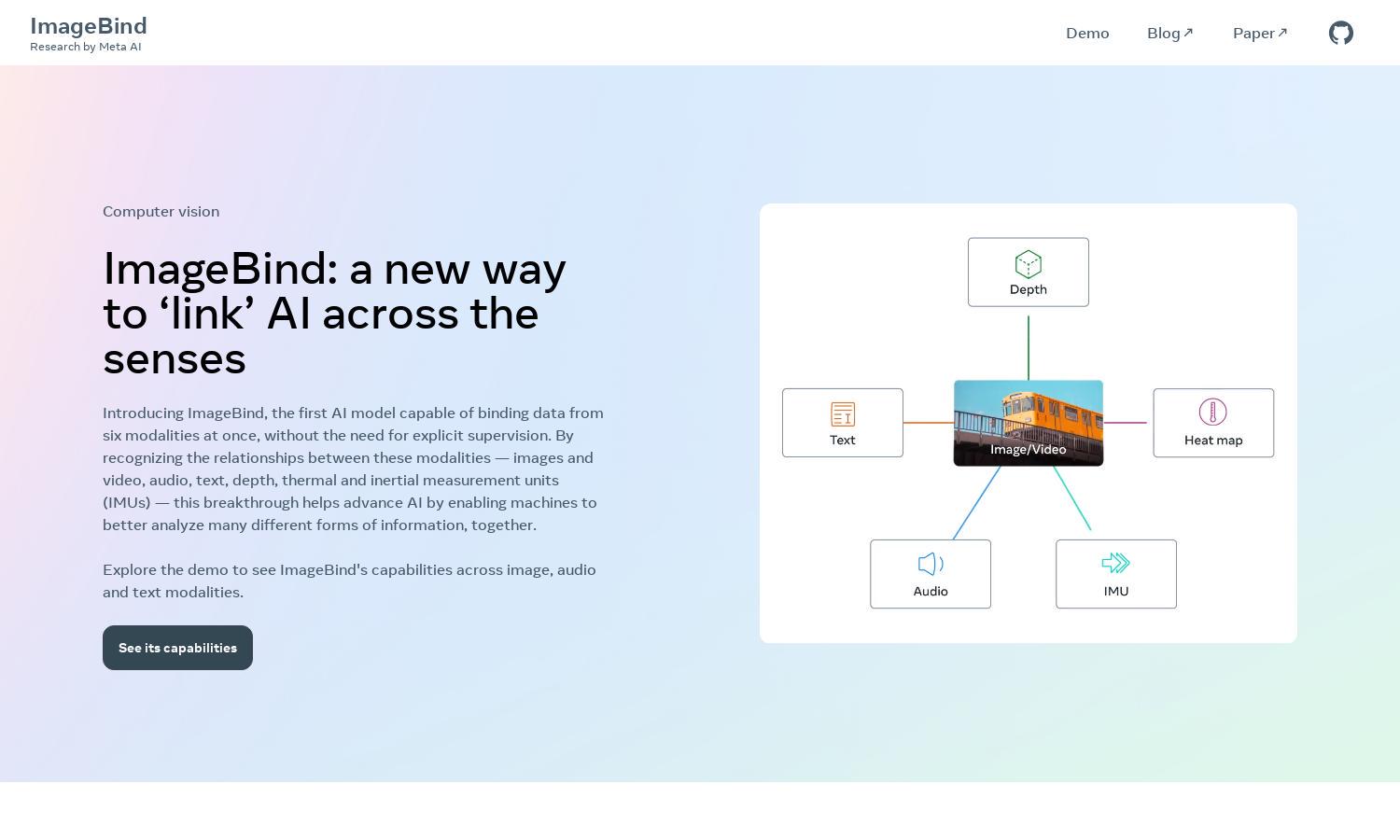
ImageBind, developed by Meta AI, is designed for advanced multimodal data analysis. This innovative platform effectively links images, audio, text, and more within a unified embedding space, greatly enhancing AI capabilities. Ideal for researchers and developers, it offers groundbreaking insights and solves complex AI challenges.
ImageBind offers users free access to its open-source model, enabling exploration of advanced AI capabilities. For professional needs, premium tiers provide additional features, such as customized support and enhanced processing power, offering significant advantages for teams requiring robust multimodal solutions.
ImageBind features a sleek, intuitive interface designed for seamless interaction. The layout ensures effortless navigation, allowing users to explore various modalities without obstacles. Unique functionalities like integrated demos and real-time analysis tools make using ImageBind efficient and user-friendly, enhancing the overall experience.
How ImageBind by Meta AI works
To interact with ImageBind, users begin by visiting the website to access the demo. After onboarding, they explore the unique multimodal capabilities, allowing for the integration of images, audio, and text. The straightforward interface guides users through real-time analysis, demonstrating how effectively the model can recognize and bind data from various inputs.
Key Features for ImageBind by Meta AI
Multimodal Integration
ImageBind excels in multimodal integration, binding data from six different modalities without explicit supervision. This unique feature offers users advanced AI capabilities, allowing for comprehensive analyses across diverse sensory inputs, enhancing performance in tasks like audio-based searches and cross-modal generation.
Zero-Shot Recognition
Another standout feature of ImageBind is its ability to perform zero-shot recognition effectively. This capability allows the model to identify and classify new categories without prior training, making it an invaluable tool for researchers and developers looking to leverage advanced AI recognition technologies.
Cross-Modal Generation
ImageBind offers cross-modal generation, enabling users to create new content or enhance existing data mutually. This distinct feature elevates user experience, allowing for innovative applications across various fields, making it a premier choice for those seeking advanced AI solutions.