Friendli Engine
About Friendli Engine
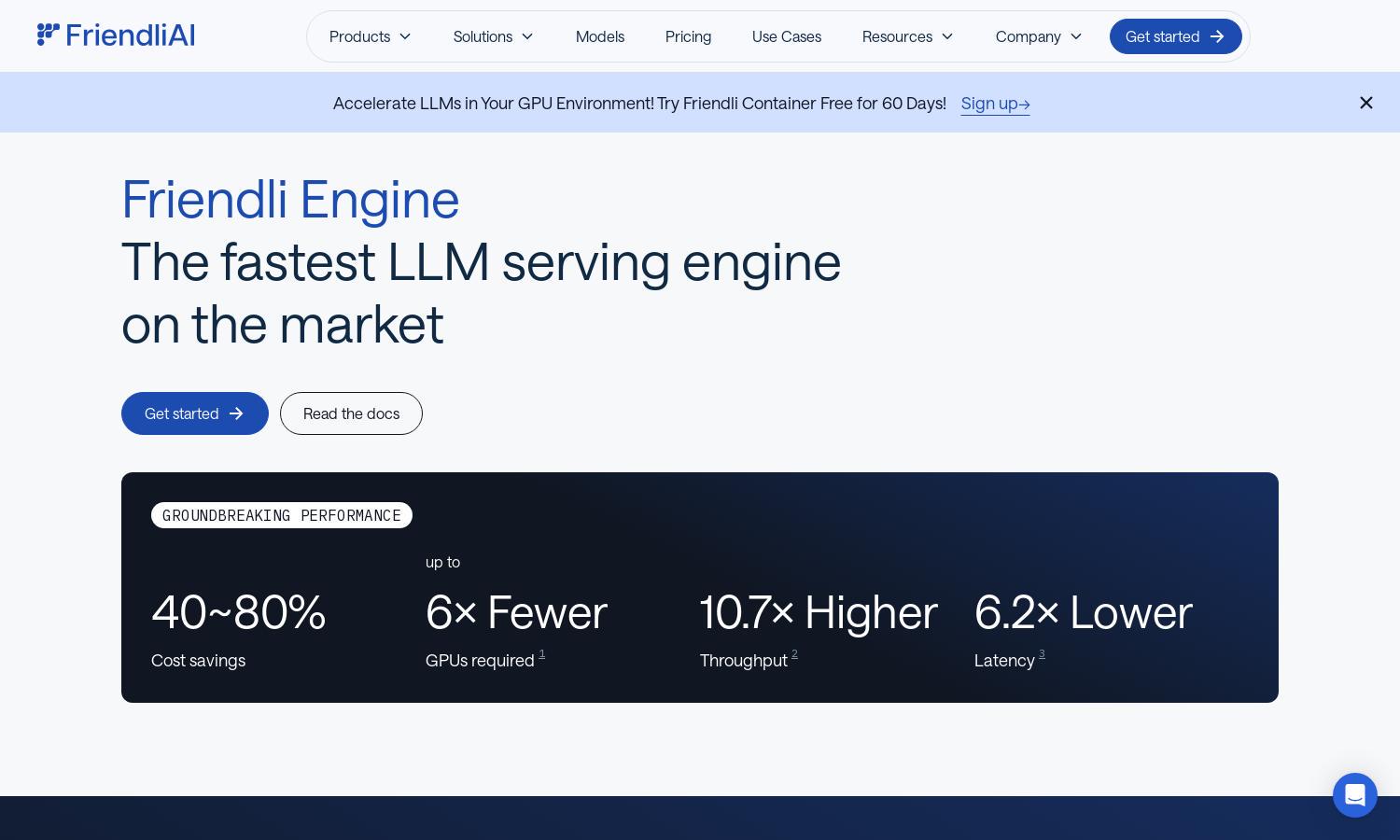
Friendli Engine revolutionizes LLM inference by providing a fast and cost-effective platform for AI model deployment. With innovative features like Iteration batching and speculative decoding, it enables users to run multiple models efficiently, solving performance issues and reducing costs dramatically, making it ideal for developers and businesses.
Friendli Engine offers flexible pricing plans, including free trials and competitive rates for Dedicated Endpoints and Serverless Endpoints. Users benefit from cost savings with scalable options, ensuring access to cutting-edge LLM technology without the high expenses usually associated with GPU usage in generative AI applications.
The user interface of Friendli Engine is designed for ease of use, featuring intuitive navigation and seamless model integration. Users can quickly access comprehensive documentation, making it user-friendly even for those new to generative AI. This layout enhances the browsing experience and facilitates efficient model management.
How Friendli Engine works
Users begin by signing up for Friendli Engine, selecting a suitable pricing plan based on their needs. Once onboarded, they can navigate the platform to access various generative AI models, utilizing features like Iteration batching for efficient requests and leveraging advanced optimizations to reduce GPU workload while maximizing performance.
Key Features for Friendli Engine
Iteration Batching
Iteration batching is a core feature of Friendli Engine that allows efficient handling of concurrent requests. This patented technology enhances LLM inference throughput by reducing processing delays, making it significantly faster than traditional batching methods, ultimately benefiting users through improved performance and cost savings.
Multi-LoRA Support
Friendli Engine's Multi-LoRA support allows users to deploy multiple models on a single GPU without compromising performance. This unique feature enhances the accessibility and efficiency of LLM customization, enabling users to experiment with different generative AI models while significantly lowering the required GPU resources.
Friendli TCache
Friendli TCache intelligently stores and reuses frequently computed results, allowing Friendli Engine to optimize time to first token (TTFT). This distinctive feature improves overall response times and reduces unnecessary computations, making the platform ideal for developers seeking rapid and efficient AI model deployment.
You may also like: